👋 Welcome to Log4Dev!
IT Knowledge Database with many best-in-class technical articles.
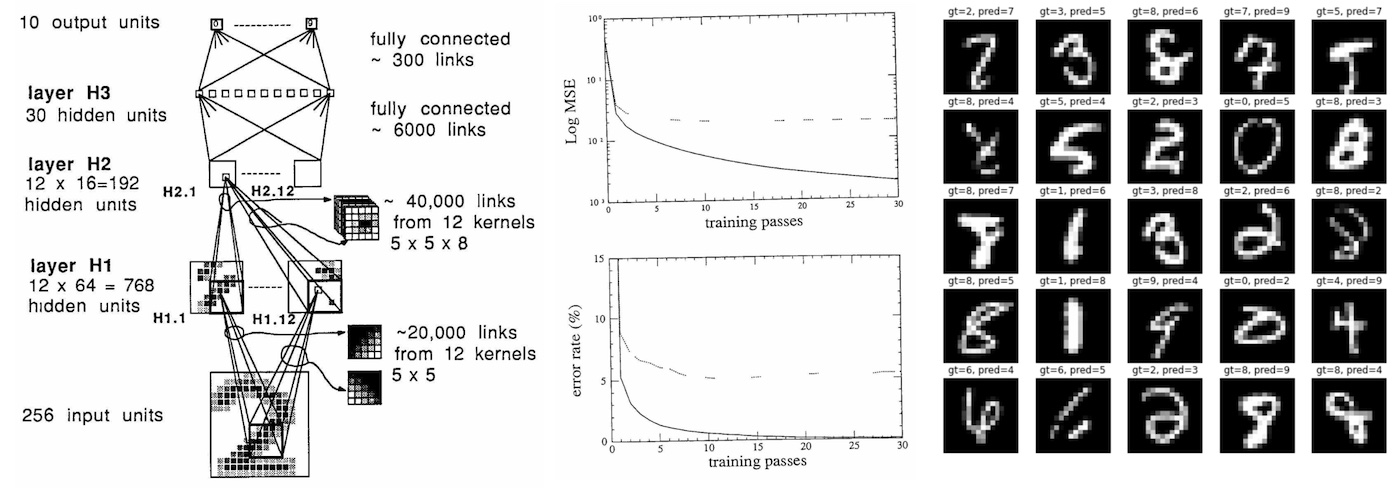
The Yann LeCun et al. (1989) paper Backpropagation Applied to Handwritten Zip Code Recognition is I believe of some historical significance because it is, to my knowledge, the earliest real-world application of a neural net trained end-to-end with backpropagation. Except for the tiny dataset (7291 16x16 grayscale images of digits) and the tiny neural network used (only 1,000 neurons), this paper reads remarkably modern today, 33 years later - it lays out a dataset, describes the neural net architecture, loss function, optimization, and reports the experimental classification error rates over training and test sets....

I’m going to be using a metaphor that not everyone can relate to since not everyone is on a speaking circuit. My hope is that this metaphor will teach you two things: how to plan a conference talk, and how to approach doing big things quickly. When you speak at a conference, whether keynote or whatever, you aren’t asked to make estimates but rather are given a time budget. You have 45 or 50 or 90 minutes....

A decade ago I first presented a lightning talk entitled Cool Code. This short talk evolved into a full talk whose iterations I presented over the next half decade. The focus? Code that, for some reason or other, can be considered cool. For example, code that has played a significant role in historical events, such as the source for the Apollo Guidance Computer . Or code that is audacious — if not seemingly impossible — given its constraints, such as David Horne’s 1K chess ....

The results of the 2014 ImageNet Large Scale Visual Recognition Challenge (ILSVRC) were published a few days ago. The New York Times wrote about it too. ILSVRC is one of the largest challenges in Computer Vision and every year teams compete to claim the state-of-the-art performance on the dataset. The challenge is based on a subset of the ImageNet dataset that was first collected by Deng et al. 2009 , and has been organized by our lab here at Stanford since 2010....

Authors, publishers, do you want to know if your books have been used to train Chat-GPT and other large language models? I’ve put a list of some 85,000 ~125,000 ISBNs of books used to train LLMs up on Github for the use of anyone looking to understand more about what books have been used as training data. See https://github.com/psmedia/Books3Info . [Ed note: my VS Code seems to have miscalculated the number of lines in that file....
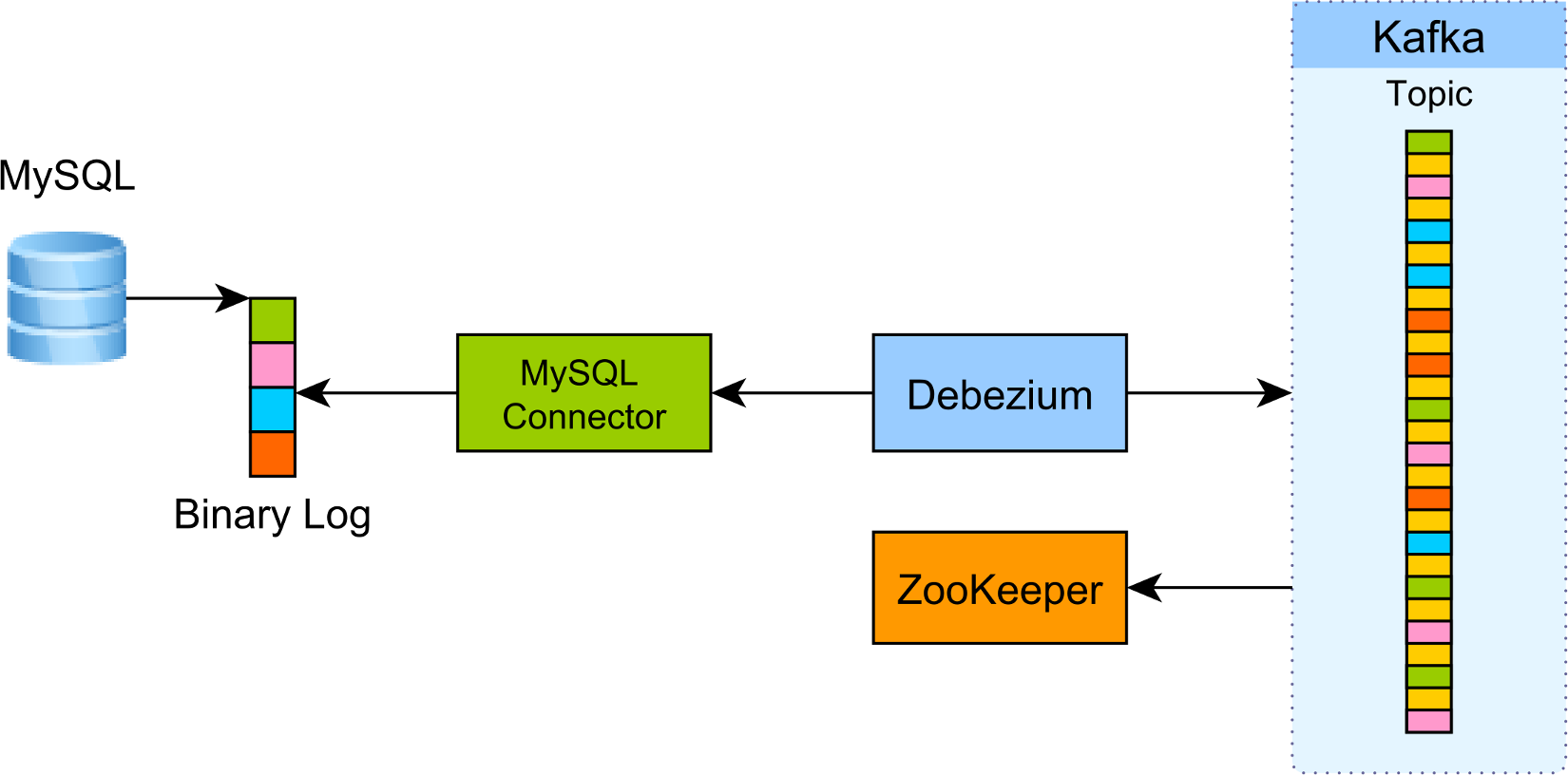
Introduction As previously explained, CDC (Change Data Capture) is one of the best ways to interconnect an OLTP database system with other systems like Data Warehouse, Caches, Spark or Hadoop. Debezium is an open-source project developed by Red Hat which aims to simplify this process by allowing you to extract changes from various database systems (e.g. MySQL, PostgreSQL, MongoDB) and push them to Apache Kafka . In this article, we are going to see how you can extract events from MySQL binary logs using Debezium....

Gary Gensler, chair of the Securities and Exchange Commission. Andrew Harrer—Getty Images In an enforcement action announced on Monday, the Securities and Exchange Commission charged Los Angeles–based entertainment company Impact Theory with conducting an unregistered offering of securities via non-fungible tokens, or NFTs . As the SEC expands its definition of which types of crypto assets qualify as securities, the case breaks new ground by determining that NFTs fall under the agency’s jurisdiction....

Photo by CA Creative / Unsplash When I was younger, I searched (as 99% of teenagers I guess) for a summer job to get some money. I ended up working as a cook in a retirement house, in one of the best work experiences I ever had. What started as a way to get money became a hobby, and I would put my toque on each time vacations would come (even on New Year’s Eve :)) for three years....

Datadog is a leading observability tooling provider which went public in 2019, with a current market cap of $28B. The company made $1.67B revenue in 2022, circa $140M per month. On an earnings call a week ago, on 4 May, the CFO mentioned a “large upfront bill that did not recur,” saying: “Billings were $511 million, up 15% year-over-year. We had a large upfront bill for a client in Q1 2022 that did not recur at the same level or timing in Q1 2023....

Jean Jennings (left) and Frances Bilas, two of the ENIAC programmers, are preparing the computer for Demonstration Day in February 1946. University Archives and Records Center/University of Pennsylvania If you looked at the pictures of those working on the first programmable, general-purpose all-electronic computer, you would assume that J. Presper Eckert and John W. Mauchly were the only ones who had a hand in its development. Invented in 1945, the Electronic Numerical Integrator and Computer (ENIAC) was built to improve the accuracy of U....