
Datadog is a leading observability tooling provider which went public in 2019, with a current market cap of $28B. The company made $1.67B revenue in 2022, circa $140M per month. On an earnings call a week ago, on 4 May, the CFO mentioned a “large upfront bill that did not recur,” saying:
“Billings were $511 million, up 15% year-over-year. We had a large upfront bill for a client in Q1 2022 that did not recur at the same level or timing in Q1 2023. Pro forma for this client, billings growth was in the low 30s percent year-over-year.”
If you’re like me, you’d probably skim over this detail, as it’s 15% here, 30% there. However, analysts attend these calls whose bread and butter is crunching the numbers and figuring out what a company might be trying to hide. A JP Morgan stock analyst did just this, quickly crunching numbers and asking the question:
“David, looking at the math on this large upfront bill that did not recur, it seems to be about $65 million, if I’m running that correctly. Can you possibly shed a little more light?“
Datadog’s CFO, David Obstler gave more details:
“That was a crypto company which continues to be a customer of ours. But that was an early optimizer. We had always talked about some of the industries that were most affected and optimized.“
So, who is this mysterious crypto company? Investor Turner Novak speculated that it’s Coinbase:
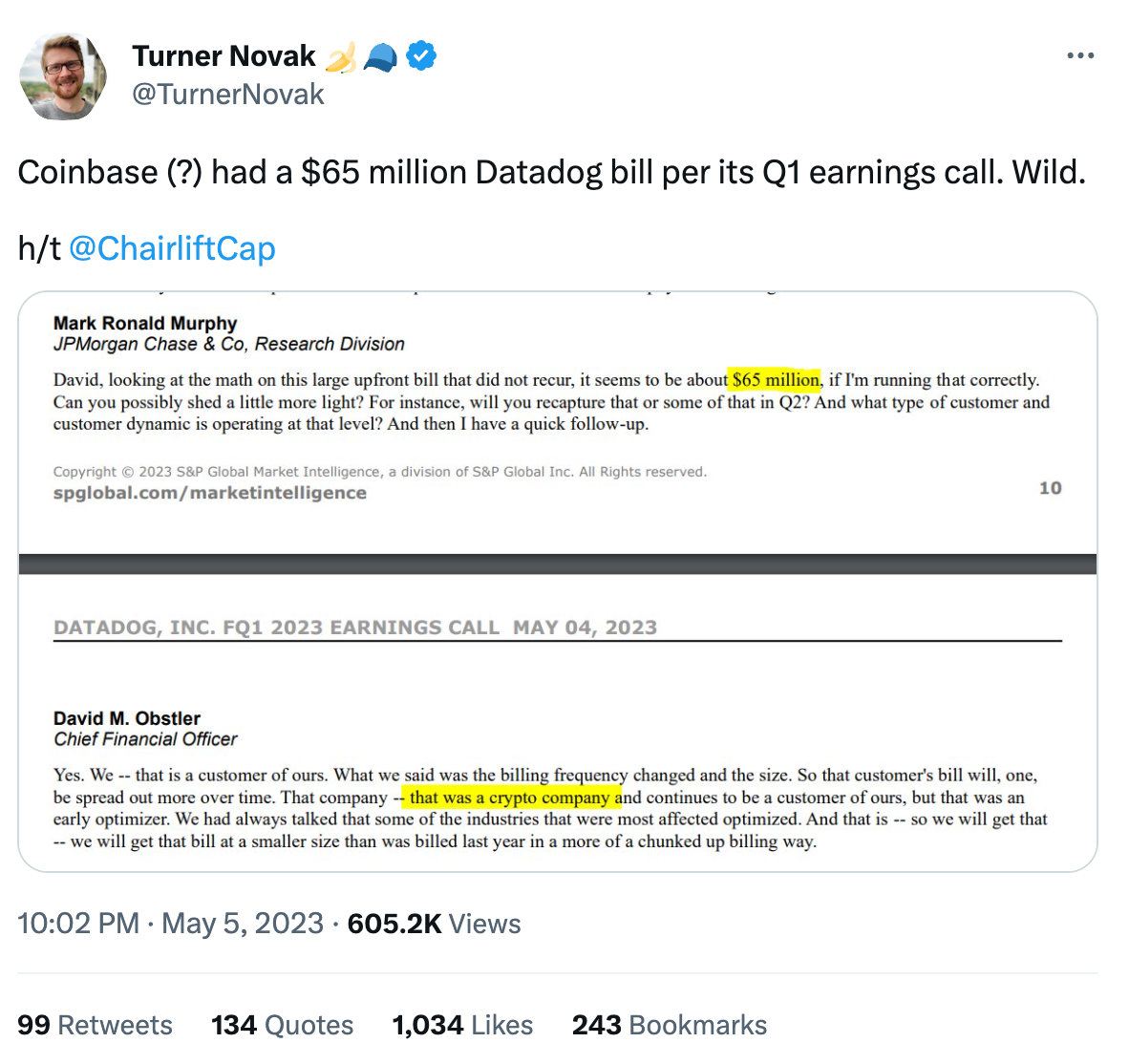
He added he doesn’t know for certain that it is Coinbase, as other crypto companies have also raised silly amounts of money in the past several years.
So, did Coinbase spend $65M on Datadog in 2022? Online there’s no shortage of theories, or people pretending to be Coinbase employees, such as this anonymous commenter on Hacker News, claiming that the $65M was for a 3-year upfront payment (which information I could not verify). I wanted to find the truth, so I tracked down software engineers at the company. And I got my answer:
Yes. Coinbase spent $65M with Datadog in 2021, and this was their due bill for that year. I can confirm this, having talked with both current and former software engineers at Coinbase who shared details of what happened.
Here’s how Datadog’s CEO explained, on the earnings call on what happened:
“This is one of those situations where this customer was in an industry that got pretty much decimated over the past year. And their own business was cut in three or four, in terms of the revenue. And when that’s the case, we really work with customers to restructure their contracts with us. We want to be part of the solution for them, not part of the problem (…) We restructure their contract, so we keep them as a happy customer for many more years and do a deal that works for everyone with their business profile.”
And here’s what actually happened, as I understand from talking with engineers at Coinbase.
Coinbase had an incredible 2021 and did not have to care about costs. The company went public in June that year, and was valued at an eye-popping $86B. In comparison, nearly two years later the company is valued around $14B, a 75% decline.
During the boom, trading volumes were surging, beating record after record, and Coinbase could barely keep up. Here’s how Coinbase CEO Brian Amstrong summarized it:
“So, obviously 2021 was just an incredible year for Coinbase, the kind of thing that you see very rarely in your lifetime, in a business career (…) We hit an all time high in our monthly transacting users of 11.4 million, which is 4x year-over-year, 400% pretty incredible.”
Following the IPO in summer 2021, nobody at the company cared about infra costs; the only focus was growth. The company racked up huge bills for the likes of AWS, Snowflake, and also Datadog. And so, the $65M bill was for Datadog, for 2021. Coinbase settled the bill in Q1 2022.
In early 2022 Coinbase suddenly needed to cut back infra spending. The crypto industry hit a sudden chill, affecting Coinbase’s business. As revenue dried up, the company turned its attention to reducing its overly high costs.
For observability, Coinbase spun up a dedicated team with the goal of moving off of Datadog, and onto a Grafana/Prometheus/Clickhouse stack. A quick summary of these technologies:
Prometheus : a time series database. A very popular open-source solution for systems and services monitoring. Prometheus collects metrics from configured targets (services) at given intervals. It evaluates rules and can trigger alerts. It’s mostly written in Go, with some Java, Python and Ruby parts. Prometheus stores time series in-memory and on storage (HDD or SSD), using an efficient and custom format, and supports sharding and federation .
Prometheus is part of the Cloud Native Foundation, membership of which indicates that it’s safe to build on top of Prometheus, as it’s actively maintained and will continue to be.
Prometheus can be self-hosted, but several cloud providers also offer managed Prometheus services: both Google Cloud and AWS have this service in production, while Azure has it in preview.
Grafana : the frontend for visualizing metrics. Grafana is a popular source analytics and monitoring visualization solution. If you need to display or dive into metrics or alerts, it’s the go-to tool, and widely used across tech companies. When I was at Uber, Grafana powered many of our graphs. Here’s an example of Grafana dashboards you can try out :
Example Grafana dashboards. Source: Grafana.org
Clickhouse : log management. A fast and open-source column-oriented database management system, which is a popular choice for log management. Clickhouse is written predominantly in C++, and is widely used across the industry. For example, Cloudflare uses Clickhouse to store all its DNS and HTTP logs – which is more than 10M rows per second! – and Uber uses Clickhouse as its central logging platform.
Coinbase spun up its in-house approach without the main goal of saving costs, but to have full control and ownership of observability. Observability and reliability is a major differentiator for Coinbase, as it gives a competitive advantage over rivals.
However, with the crypto market cooling, costs became a major focus, and it was clear the in-house Grafana/Prometheus solution was much cheaper. The Coinbase team had been double-writing the new stack for months, confirming everything worked well, and ironing out any issues.
We cover approaches like double-writing in the issue Migrations done well .
So Coinbase was ready to pull the plug on Datadog, but Datadog saved its customer relationship at the last minute by making Coinbase a very appealing deal it could not refuse. In future, the bill for Datadog would be nowhere near the $65M of 2021. As Brian Amstrong said of the crypto market during 2021, a $65M bill is the kind of thing you see very rarely in a business career.
I asked an engineer at Coinbase who used the in-house stack and Datadog how they felt about the decision to stay on Datadog. They said it was ultimately the right decision, considering the reasonable costs, and the superior Datadog development experience.
Coinbase could eventually have engineered a similar experience in-house. However, to provide a similarly seamless developer experience, would have likely taken tens of engineering years.
“Expensive” in observability tooling is relative. Let’s assume that today Coinbase “only” spends, say, $10M per year on Datadog. Is this too much? Looking at the headline number, it’s tempting to think so.
However, let’s look a level deeper. A platform like Datadog helps prevent outages, detects them instantly, and mitigates them faster. In 2022, Coinbase had 17 outages, totalling about 12 hours of downtime. The company’s daily average revenue is around $9M/day, based on their 2022 earnings.
Assume that Datadog cuts the number of outages by half, by preventing them with early monitoring. That would mean that without Datadog, we’d look at 24 hours’ worth of downtime, not 12. Let’s also assume that using Datadog results in mitigating outages 50% faster than without - thanks to being able to connect health metrics with logs, debug faster, pinpoint the root cause and mitigate faster. In that case, without Datadog, we could be looking at 36 hours worth of total downtime, versus the 12 hours with Datadog. To put it in numbers: the company would make around $9M in revenue it would otherwise lose, Now that $10M/year fee practically pays for itself!
What can we learn from Coinbase’s cost reduction exercise? Vendors are tight-lipped about their customers reducing spend, and it is a lucky coincidence that Datadog gave enough hints to find out who their big “early optimizer” customer was, and find out more details. But is the story of Coinbase a one-off?
I’m not sure that it is. Three months ago, I covered the trend that Tech companies are aggressively cutting back on vendor spend - and two months later, The Wall Street Journal also reported on the same topic. Coinbase, to me, seems to have been early to the cost optimizing trend. However, look closely at the responses I gathered, and “AWS” and “Datadog” are the two most mentioned vendors as targets for cost savings. This is simply because infra and observability costs tend to be the highest and AWS is the leader for cloud infra, and Datadog the leader for observability.
Datadog CEO Olivier Pomel confirmed that this type of optimization is happening across all of their customers, saying:
“When we look at our data, when we look at what we hear from the hyperscalers also, we also listen carefully to their commentary on what they foresee in the near future, we don’t see anything that gives us confidence that we can call an end to optimization in the next quarter or the quarter after that. So as far as our guidance goes and our plan for the year, we assume that this is going to continue at a similar level for the rest of the year.”
I have since confirmed several large companies with thousands of engineers building their own Grafana/Prometheus stack, planning to migrate off of their current observability vendor and operate the observability stack themselves. But why is this?
Above $2-5M/year annual spend is where bringing a vendor in-house tends to come up. And this is because it is around this number where the cost of hiring a whole team to do what a vendor is doing can theoretically make sense.
As a rule of thumb, you can get infra costs much lower than what vendors charge. This is because both the vendor, and you are probably using the same Cloud infrastructure provider, which is usually AWS, GCP or Azure. However, you would need to hire and staff a dedicated engineering team to build and run that infra.
So, from a cost perspective, this is the math problem you need to solve. At what point does is this equation become true:
$infra_cost + $platform_team_cost < $current_vendor_costs
In this question, $platform_team_costs will be above $1M, and sometimes above $2M. This is because you need to have a team of 4-5 engineers, plus a manager, and their average total compensation will be somewhere between $150-400K/year, depending on your cost basis.
So when you have a bill that is above $2-3M/year, it can start to look tempting to build, rather than buy. The economics of this decision start to get down to how high of a margin is the vendor charging on top of raw infra? The curious question with Coinbase is: did they consider building, when talking about such a huge projected cost that could justify having a team?
In the case of Coinbase, building in-house following a $65M bill was a clear no-brainer. They could hire a team of 10 senior and staff-level engineers in the Bay Area, and still have this team cost less than $5M/year. And they then only need to budget for the infra costs, which they can presumably bring down to low double digits per year.
Coinbase planned to move off Datadog, but ended up staying. However, it is not the only larger tech company thinking about bringing observability in house. I have another exclusive which even Datadog might not be aware of, yet. This report is about Shopify and its plan to move off Datadog. But could recent layoffs change things? I cover details on this topic in the full The Scoop .
This was one out of the five topics covered in this week’s The Scoop. A lot of what I share in The Scoop is exclusive to this publication, meaning it’s not been covered in any other media outlet before and you’re the first to read about it.
The full The Scoop edition additionally covers:
- Will Shopify migrate onto an in-house observability tool? Shopify decided to build its own observability platform and migrate off Datadog. This plan looked certain until Shopify cut the very engineering teams that built its new platform. What happens next?** Exclusive**.
- Microsoft cuts its compensation targets. Almost exactly a year ago, Microsoft employees received a welcome surprise: they could expect higher-than-usual compensation increases. Yesterday, another unexpected email came, but its contents were the opposite of last year’s. I talked with managers and engineers at the tech giant for their reaction to disappointing compensation news. Exclusive.
- Shopify letting go most staff in Germany. As part of cutting 20% of staff, most people in Germany were made redundant. These layoffs happened a week before a Works Council election in Germany. Is this unlucky timing, or is there more behind the move?** Exclusive**.
- Senior compensation trending down in Ukraine. Ukraine is one of the few countries for which we have access to nationwide data, through job site Djinni. Data for the first part of this year are in, and they point to something not seen recently: senior engineers are making less. Is this a local trend, or could we see it happening in other countries?**** Analysis.
- A follow-up to this week’s public tech company compensation article. Why was Netflix lower down the list than many software engineers expected? Plus, new details about Roblox and why Jack Dorsey’s total compensation is $2.75. Follow-up.