Programming paradigms for dummies: what every programmer should know Peter Van Roy, 2009
We’ll get back to CIDR’19 next week, but chasing the thread starting with the Data Continuum paper led me to this book chapter by Peter Van Roy mapping out the space of programming language designs. (Thanks to TuringTest for posting a reference to it in a HN thread
). It was too good not to take a short detour to cover it! If you like the chapter, you’ll probably enjoy the book, ‘Concepts, Techinques, and Models of Computer Programming
’ by Van Roy & Haridi on which much of this chapter was based .
This chapter gives an introduction to all the main programming paradigms, their underlying concepts, and the relationships between them… We give a taxonomy of about 30 useful programming paradigms and how they are related.
Programming paradigms are approaches based on a mathematical theory or particular set of principles, each paradigm supporting a set of concepts. Van Roy is a believer in multi-paradigm languages: solving a programming problem requires choosing the right concepts, and many problems require different sets of concepts for different parts. Moreover, many programs have to solve more than one problem! “A language should ideally support many concepts in a well-factored way, so that the programmer can choose the right concepts whenever they are needed without being encumbered by the others.” That makes intuitive sense, but in my view does also come with a potential downside: the reader of a program written in such a language needs to be fluent in multiple paradigms and how they interact. (Mitigating this is probably what Van Roy had in mind with the ‘well-factored’ qualification: a true multi-paradigm language should avoid cross-paradigm interference, not just support a rag-bag of concepts). As Van Roy himself says later on when discussing state: “The point is to pick a paradigm with just the right concepts. Too few and programs become complicated. Too many and reasoning becomes complicated.“
There are a huge number of programming languages, but many fewer paradigms. But there are still a lot of paradigms. This chapter mentions 27 different paradigms that are actually used.
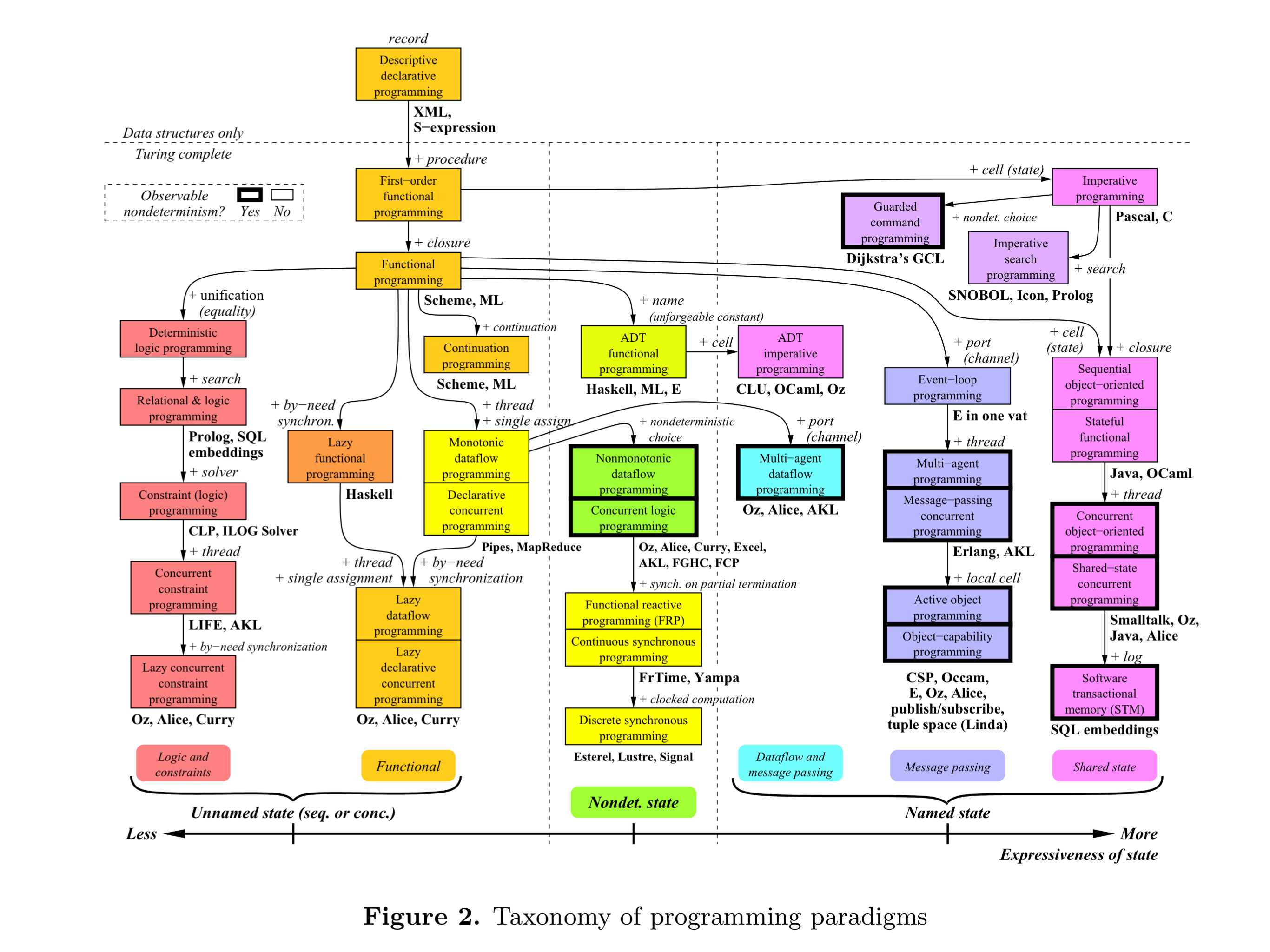
The heart of the matter is captured in the following diagram, “which rewards careful study.” Each box is a paradigm, and the arrows between boxes show the concept(s) that need to be added to move between them.

Figure 2 is organised according to the creative extension principle:
Concepts are not combined arbitrarily to form paradigms. They can be organized according to the the creative extension principle… In a given paradigm, it can happen that programs become complicated for technical reasons that have no direct relationship to the specific problem that is being solved. This is a sign that there is a new concept waiting to be discovered.
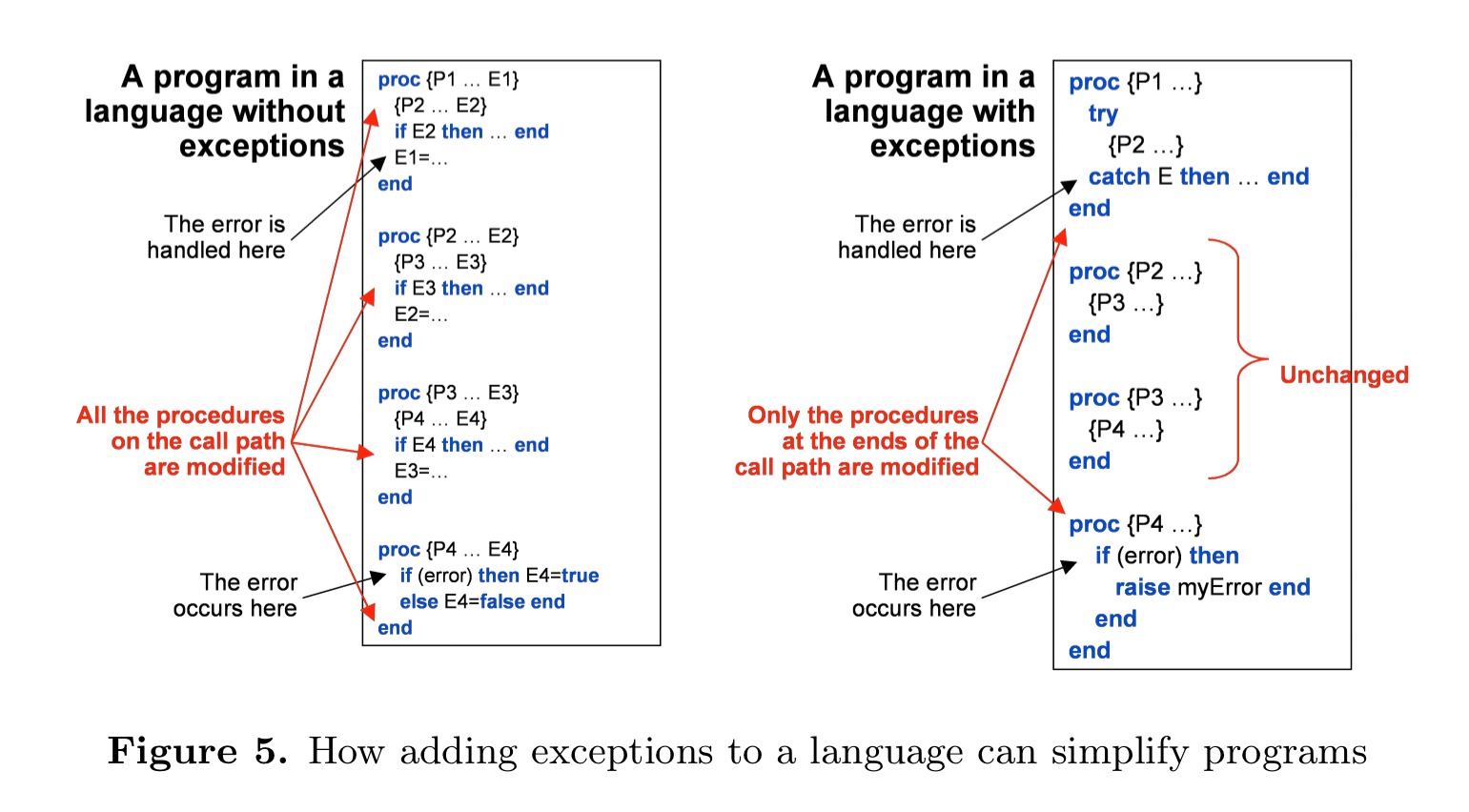
The most common ‘tell’ is a need to make pervasive (nonlocal) modifications to a program in order to achieve a single objective. (I’m in danger of climbing back on my old AOP soapbox here!). For example, if we want any function to be able to detect an error at any time and transfer control to an error correction routine, that’s going to be invasive unless we have a concept of exceptions.
Two key properties of a programming paradigm are whether or not it has observable non-determinism, and how strongly it supports state.
… non-determinism is observable if a user can see different results from executions that start at the same internal configuration. This is highly undesirable… we conclude that observable nondeterminism should be supported only if its expressive power is needed.
Regarding state, we’re interested in how a paradigm supports storing a sequence of values in time. State can be unnamed or named; deterministic or non-determinstic; and sequential or concurrent. Not all combinations are useful! Figure 3 below shows some that are:
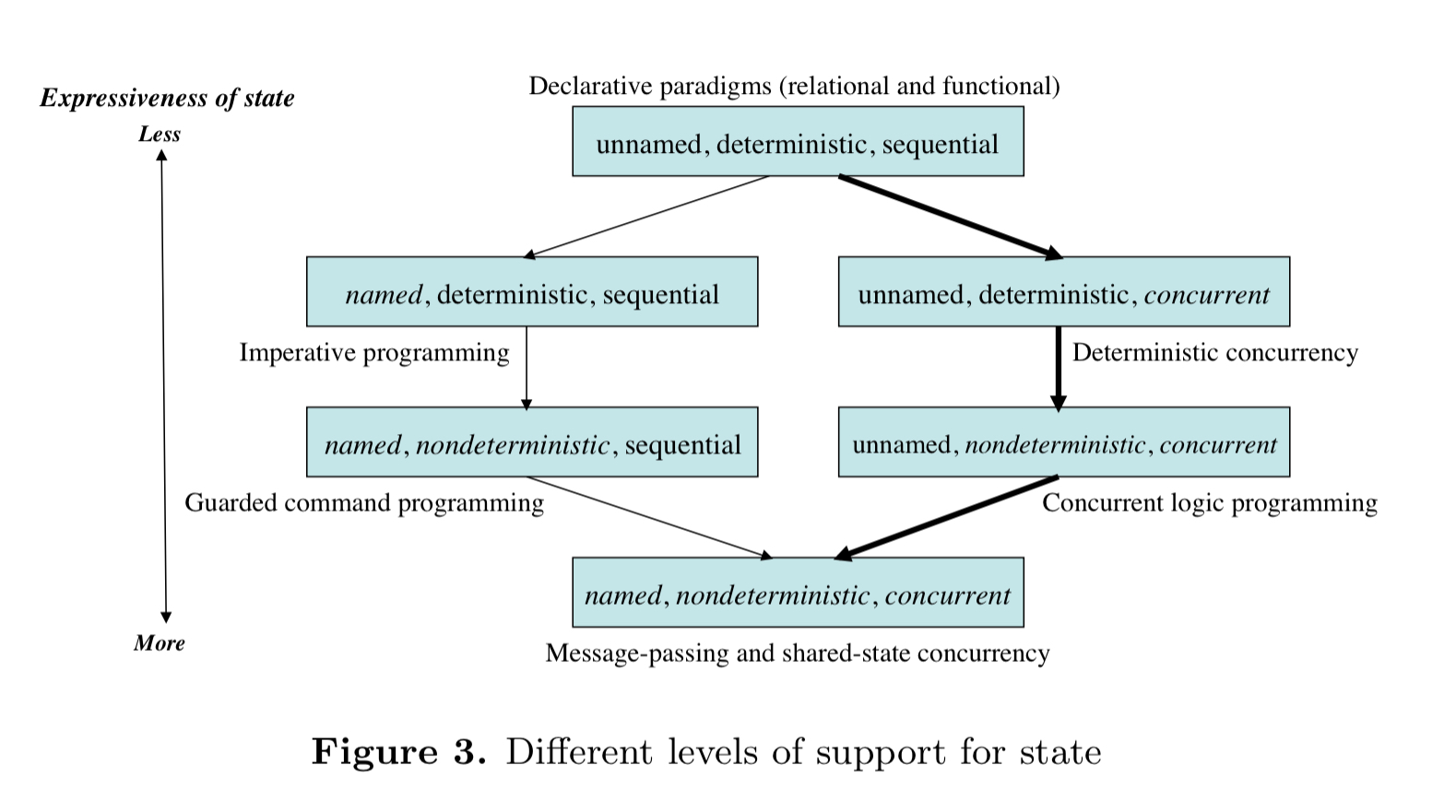
The horizontal axis in the main paradigms figure (figure 2) is organised according to the bold line in the figure above.
The four most important programming concepts
The four most important programming concepts are records, lexically scoped closures, independence (concurrency) and named state.
Records are groups of data items with indexed access to each item (e.g. structs). Lexically scoped closures combine a procedure with its external references (things it references outside of itself at its definition). They allow you to create a ‘packet of work’ that can be passed around and executed at a future date. Independence here refers to the idea that activities can evolve independently. I.e., they can be executed concurrently. The two most popular paradigms for concurrency are shared-state and message-passing. Named state is at the simplest level the idea that we can give a name to a piece of state. But Van Roy has a deeper and very interesting argument that revolves around named mutable state:
State introduces an abstract notion of time in programs. In functional programs, there is no notion of time… Functions do not change. In the real world, things are different. There are few real-world entities that have the timeless behaviour of functions. Organisms grows and learn. When the same stimulus is given to an organism at different times, the reaction will usually be different. How can we model this inside a program? We need to model an entity with a unique identity (its name) whose behaviour changes during the execution of the program. To do this, we add an abstract notion of time to the program. This abstract time is simply a sequence of values in time that has a single name. We call this sequence a named state.
Then Van Roy goes on to give what seems to me to be conflicting pieces of advice: “A good rule is that named state should never be invisible: there should always be some way to access it from the outside” (when talking about correctness), and “Named state is important for a system’s modularity” (think information hiding ).
Abstracting data
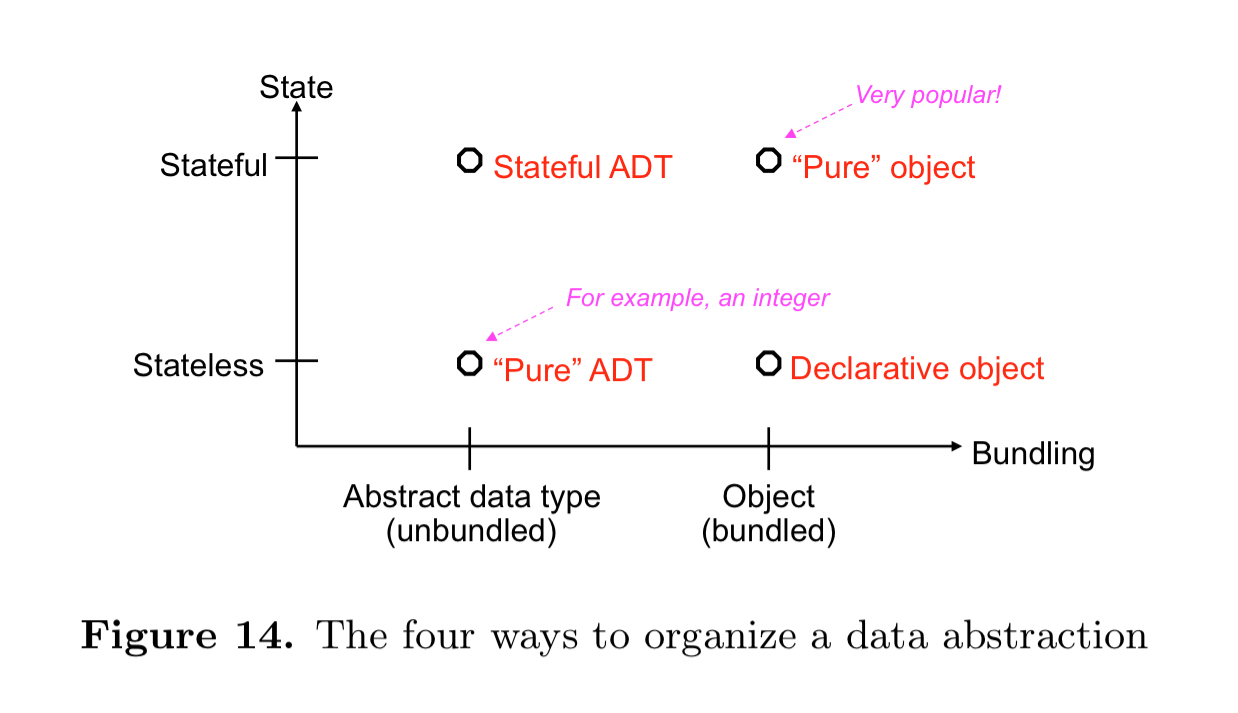
A data abstraction is a way to organize the use of data structures according to precise rules which guarantee that the data structures are used correctly. A data abstraction has an inside, an outside, and an interface between the two.
Data abstractions can be organised along two main dimensions: whether or not the abstraction uses named state, and whether or not the operations are bundled into a single entity with the data.
Van Roy then goes on to discuss polymorphism and inheritance (note that Van Roy prefers composition to inheritance in general, but if you must use inheritance then make sure to follow the substitution principle).
Concurrency
The central issue in concurrency is non-determinism.
Nondeterminism is very hard to handle if it can be observed by the user of the program. Observable nondeterminism is sometimes called a race condition…
Not allowing non-determinism would limit our ability to write programs with independent parts. But we can limit the observability of non-determinate behaviour. There are two options here: defining a language in such a way that non-determinism cannot be observed; or limiting the scope of observable non-determinism to those parts of the program that really need it.
There are at least four useful programming paradigms that are concurrent but have no observable non-determinism (no race conditions). Table 2 (below) lists these four together with message-passing concurrency.
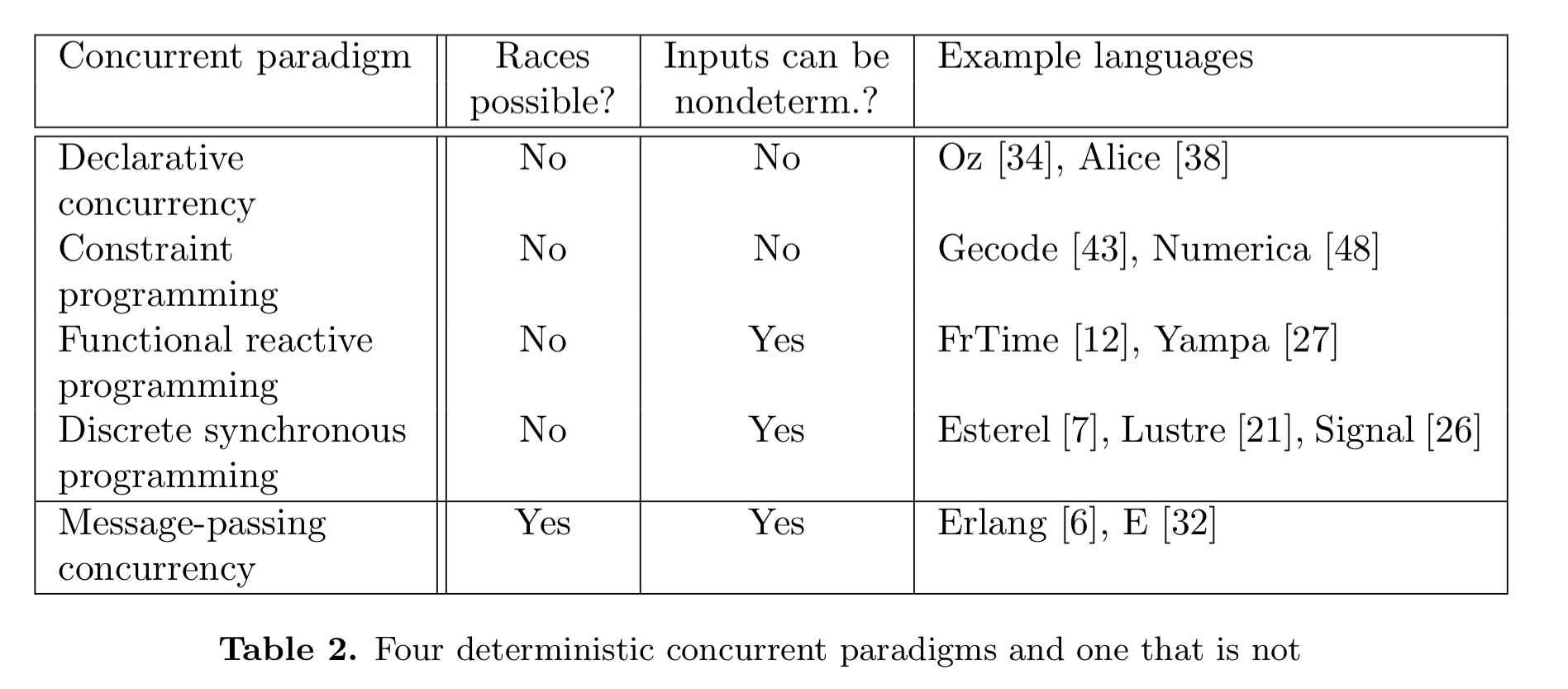
Declarative concurrency is also known as monotonic dataflow. Deterministic inputs are received and used to calculate deterministic outputs.
In functional reactive programming, FRP, (aka ‘continuous synchronous programming’) we write function programs but the function arguments can be changed and the change is propagated to the output.
Discrete synchronous programming (aka reactive) systems wait for input events, perform internal calculations, and emit output events. The main difference between reactive and FRP is that in reactive programming time is discrete instead of continuous.
Constraints
In constraint programming we express the problem to be solved as a constraint satisfaction problem (CSP)… Constraint programming is the most declarative of all practical programming paradigms.
Instead of writing a set of instructions to be executed, in constraint programming you model the problem: representing the problem as a set of variables with constraints over those variables and propagators that implement the constraints. You then pass this model to a solver.
Language design guidelines
Now that we’ve completed a whirlwind tour through some of the concepts and paradigms, I want to finish up with some of Van Roy’s thoughts on designing a programming language. One interesting class of language is the ‘dual-paradigm’ language. A dual-paradigm language typically supports one paradigm for programming in the small, and another for programming in the large. The second paradigm is typically chosen to support abstraction and modularity. For example, solvers supporting constraint programming embedded in an OO language.
More generally, Van Roy sees a layered language design with four core layers, a structure which has been independently discovered across multiple projects:
The common language has a layered structure with four layers: a strict functional core, followed by declarative concurrency, then asynchronous message passing, and finally global named state. This layered structure naturally supports four paradigms.
Van Roy draws four conclusions from his analysis here:
- Declarative programming is at the very core of programming languages.
- Declarative programming will stay at the core for the foreseeable future, because distributed, secure, and fault-tolerant programming are essential topics that need support from the programming language
- Deterministic concurrency is an important form of concurrency that should not be ignored. It is an excellent way to exploit the parallelism of multi-core processors.
- Message-passing concurrency is the correct default for general-purpose concurrency instead of shared-state concurrency.
For large-scale software systems, Van Roy believes we need to embrace a self-sufficient style of system design in which systems become self-configuring, healing, adapting, etc.. The system has components as first class entities (specified by closures), that can be manipulated through higher-order programming. Components communicate through message-passing. Named state and transactions support system configuration and maintenance. On top of this, the system itself should be designed as a set of interlocking feedback loops. Here I’m reminded of systems thinking and causal loop diagrams .
The last word
Each paradigm has its own “soul” that can only be understood by actually using the paradigm. We recommend that you explore the paradigms by actually programming in them…